Recall that in the lessons on numpy arrays, you ran multiple functions to get the mean, minimum and maximum values of numpy arrays. This fast calculation of summary statistics is one benefit of using pandas dataframes. Run calculations and summary statistics (e.g. mean, minimum, maximum) on columns in pandas dataframes.

Previous chapters in this textbook have introduced the concept of functions as commands that can take inputs that are used to produce output. According to mathematical perceptions there are several ways to denote the word mean. The most common method to represent the term means is it is the sum of all the terms divided by the total number of terms.

Applying this formula gives the mean value for a given set of values. In pandas of python programming the value of the mean can be determined by using the Pandas DataFrame.mean() function. This function can be applied over a series or a data frame and the mean value for a given entity can be determined across specific access.

For example, you used .shape to get the structure (i.e. rows, columns) of a specific numpy array using array.shape. This attribute .shape is automatically generated for a numpy array when it is created. Pandas dataframe.mean() function return the mean of the values for the requested axis. If the method is applied on a pandas series object, then the method returns a scalar value which is the mean value of all the observations in the dataframe. If the function is applied to a Series, it returns a scalar value that is the average value of all observations in the dataframe. If the method is applied to a dataframe object, it returns a pandas series object that contains the average of the values on the specified axis.

You have now learned how to run calculations and summary statistics on columns in pandas dataframes. On the next page, you will learn various ways to select data from pandas dataframes, including indexing and filtering of values. You can use the method .info() to get details about a pandas dataframe (e.g. dataframe.info()) such as the number of rows and columns and the column names. Here, we first created a subset of the dataframe "df" with only the columns "petal_length" and "petal_width" and then applied the mean function.

Descriptive statistics include those that summarize the central tendency, dispersion and shape of a dataset's distribution, excluding NaN values. Analyzes both numeric and object series, as well as DataFrame column sets of mixed data types. To find the mean of the values over rows or columns in DataFrame in Pandas, call mean() method on this DataFrame. Mean() method returns a Series with the mean calculated over specified axis. In this chapter, you will explore some methods (i.e. functions specific to certain objects) that are accessible for pandas dataframes.

In this post, you learned how to calculate the Pandas mean, using the.mean()method. You learned how to calculate a mean based on a column, a row, multiple columns, and the entire dataframe. Additionally, you learned how to calculate the mean by including missing values. Rather than column-wise obtaining the mode, median, std, etc. using the relevant functions, describe() function can be used.

It gives the summarized version of the calculated mode, median, std, max, min, percentile values as shown in figure 18. The median can be calculated using the median()function. Specify the data frame you want to find the median and then use the median function. As discussed in the above sections, this function also can be used to find out the median of a particular column or all the columns . The Pandas DataFrame std() function allows to calculate the standard deviation of a data set.

The standard deviation is usually calculated for a given column and it's normalised by N-1 by default. The degrees of freedom of the standard deviation can be changed using the ddof parameter. You have also used functions provided by Python packages such as numpy to run calculations on numpy arrays. For example, you used np.mean() to calculate the average value of specified numpy array. To run these numpy functions, you explicitly provided the name of the variable as an input parameter.

This function returns nan if there are nan values in your NumPy array. If you use a Pandas Series object, then it will return a number. This code uses .mode to return the smallest mode in the array v and .count to return the number of times it occurs . It allows you to define desired behavior with the optional parameter nan_policy. This parameter can take on the values 'propagate', 'raise' , or 'omit'.

This function returns the object with the modal value and the number of times it occurs. If there are multiple modal values in the dataset, then only the smallest value is returned. It returns the same value as mean() if you were to apply it to the dataset without the nan values. They're almost the same, with the difference that x_with_nan contains a nan value. It's important to understand the behavior of the Python statistics routines when they come across a not-a-number value . In data science, missing values are common, and you'll often replace them with nan.

You can apply descriptive statistics to one or many datasets or variables. When you describe and summarize a single variable, you're performing univariate analysis. When you search for statistical relationships among a pair of variables, you're doing a bivariate analysis.

Similarly, a multivariate analysis is concerned with multiple variables at once. To calculate the mean of a sample of numeric data, we'll use two of Python's built-in functions. One to calculate the total sum of the values and another to calculate the length of the sample. Using mean () method, you can calculate mean along an axis, or the complete DataFrame. In this example, we will calculate the mean along the columns.
We will come to know the average marks obtained by students, subject wise. You can use the describe() function of the pandas module. It returns the basic summary of the data in each column and the summary includes mean and standard deviation too. The mean() function is used to return the mean of the values for the requested axis. If we apply this method on a Series object, then it returns a scalar value, which is the mean value of all the observations in the dataframe. You can use the pandas series mean() function to get the mean of individual columns .

For example, let's get the mean of the "sepal_length" column in the above dataframe. In this post, you'll learn how to calculate the Pandas mean for one column, multiple columns, or an entire dataframe. You'll also learn how to skipnavalues or include them in your calculation. If you have nan values in a dataset, then gmean() will return nan.

If there's at least one 0, then it'll return 0.0 and give a warning. If you provide at least one negative number, then you'll get nan and the warning. With a single-mode sample, Python's mode() returns the most common value, 2. However, in the proceeding two examples, it returned 4 and few. These samples had other elements occurring the same number of times, but they weren't included. The Counter class provides a method defined as .most_common().

This method returns a list of two-items tuples with the n more common elements and their respective counts. If n is omitted or None, then .most_common() returns all of the elements. This function takes a sample of numeric values and returns its median.

Then, we calculate the index of the middle value (or upper-middle value) by dividing n by 2. The most common aggregation functions are a simple average or summation of values. As of pandas 0.20, you may call an aggregation function on one or more columns of a DataFrame. One of the most basic analysis functions is grouping and aggregating data. In some cases, this level of analysis may be sufficient to answer business questions. In other instances, this activity might be the first step in a more complex data science analysis.
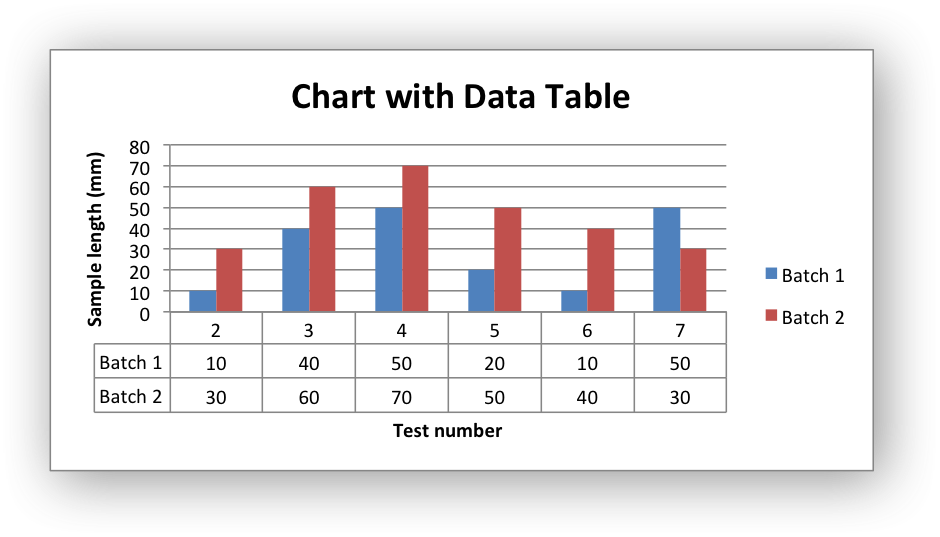
In pandas, the groupbyfunction can be combined with one or more aggregation functions to quickly and easily summarize data. This concept is deceptively simple and most new pandas users will understand this concept. However, they might be surprised at how useful complex aggregation functions can be for supporting sophisticated analysis. The mean is the average value of a given set of values. The mean can be calculated by using the mean() function. As the functions we discussed previously this function can be used to get the mean of a particular column or all the columns.

The number of records in a particular column can be printed by specifying the data frame, the column name with the count function as shown in figure 2. Assume that the count of the records in the Quantity column is needed to be printed out. Otherwise, only the ones with different values are kept. In this article we will discuss how to replace the NaN values with mean of values in columns or rows using fillna() and mean() methods. Again, the Pandas mean technique is most commonly used for data exploration and analysis.

When we analyze data, it's very common to examine summary statistics like mean, median, minimum, maximum, etc. Pandas documentation provides a list of all attributes and methods of pandas dataframes. From the previous example, we have seen that mean() function by default returns mean calculated among columns and return a Pandas Series. Apply mean() on returned series and mean of the complete DataFrame is returned. Df.values and df.to_numpy() give you a NumPy array with all items from the DataFrame without row and column labels. Note that df.to_numpy() is more flexible because you can specify the data type of items and whether you want to use the existing data or copy it.

As you can see, you get statistics across all data in the array a. Sometimes, this behavior is what you want, but in some cases, you'll want these quantities calculated for each row or column of your 2D array. With SciPy, you're just one function call away from a descriptive statistics summary for your dataset.

This code calculates the 25th, 50th, and 75th percentiles all at once. If the percentile value is a sequence, then percentile() returns a NumPy array with the results. The second statement returns the median, so you can confirm it's equal to the 50th percentile, which is 8.0. Like other methods, .skew() ignores nan values by default, because of the default value of the optional parameter skipna.

The obtained result is the same as the pure Python implementation. The parameter bias is set to False to enable the corrections for statistical bias. The optional parameter nan_policy can take the values 'propagate', 'raise', or 'omit'. As you can see, you can determine the standard deviation in Python, NumPy, and Pandas in almost the same way as you determine the variance. You use different but analogous functions and methods with the same arguments. Note that, in many cases, Series and DataFrame objects can be used in place of NumPy arrays.
Often, you might just pass them to a NumPy or SciPy statistical function. In addition, you can get the unlabeled data from a Series or DataFrame as a np.ndarray object by calling .values or .to_numpy(). In this tutorial, we've learned how to find or compute the mean, the median, and the mode using Python.

The pandas standard aggregation functions and pre-built functions from the python ecosystem will meet many of your analysis needs. However, you will likely want to create your own custom aggregation functions. There are four methods for creating your own functions.

The tuple approach is limited by only being able to apply one aggregation at a time to a specific column. If I need to rename columns, then I will use the renamefunction after the aggregations are complete. In some specific instances, the list approach is a useful shortcut. I will reiterate though, that I think the dictionary approach provides the most robust approach for the majority of situations.
One area that needs to be discussed is that there are multiple ways to call an aggregation function. As shown above, you may pass a list of functions to apply to one or more columns of data. In the context of this article, an aggregation function is one which takes multiple individual values and returns a summary. In the majority of the cases, this summary is a single value. Assume that we need to calculate the mean of the Quantity column. I have a data frame where most of the columns are varchar/object type.
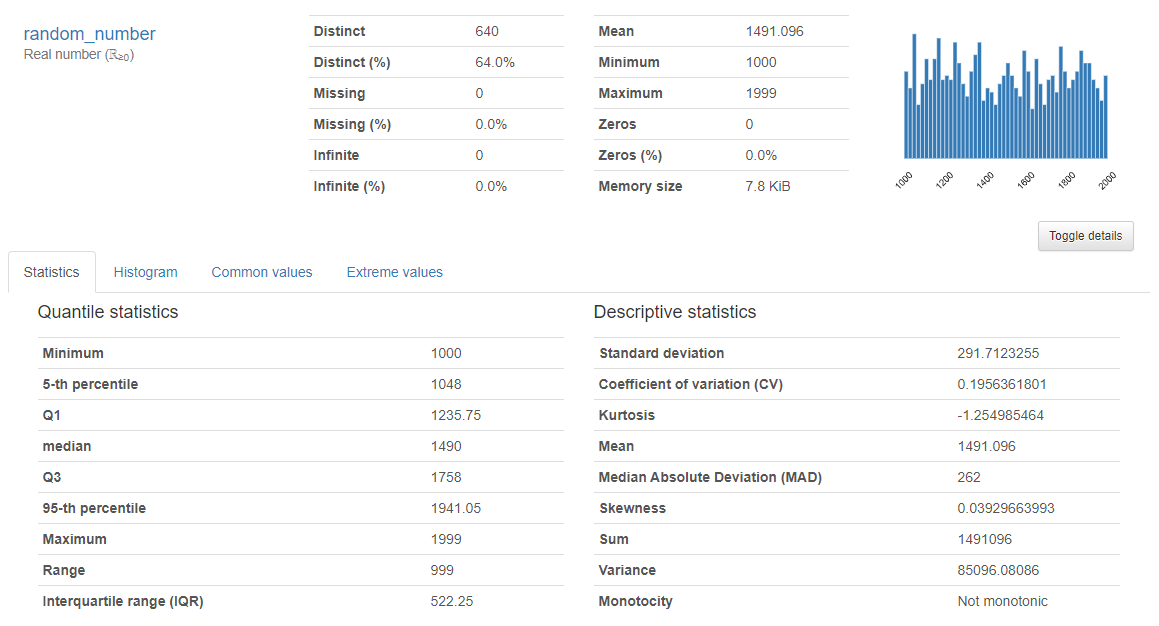
Length of the column varies a lot and could be anything within the range of 3 – 1000+ . Now, for each column, I want to measure maximum length. Pandas DataFrame class has the method mad() that computes the Mean Absolute Deviation for rows or columns of a pandas DataFrame object. DataFrame that shows the differences stacked side by side. We will see how to calculate the standard deviation of a specific column. We will then refactor our code to make it more generic.

The average is taken over the flattened array by default, otherwise over the specified axis.float64 intermediate and return values are used for integer inputs. In this Pandas Tutorial, we learned how to find the mean of DataFrame along rows or columns using pandas DataFrame.mean() method. Let us now understand the syntax and the parameters of the mean function.


